Amalgamation of Data Science and Web Development Pipeline for Data-Science Products

Blog article by Nikhil Cherian
1.
Experience of working in Data Science and Software Development Projects
As a modern Data Scientist, one is expected to perform like “Athena” - the Greek Goddess of Wisdom. It would be a daring task to work on multi-faceted roles like Data Analyst, Software Developer along with Data Science tasks like building Deep Learning models. In the same way, Genie Enterprise, a budding start-up situated in Ludwigshafen, Germany, builds Data Science tools and services for bigger companies in various fields like insurance, health and government research projects. Most of the time is spent on developing products with Data Science models which will help our customers automate their tasks and speed up their processes. We are a group of 5 people working simultaneously on both the Data Science part and the Software Developing tasks. Most of us were not even acquainted with the Software Development tools, like Angular and Spring Boot, as we all come from Data Science backgrounds. But still, Genie Enterprise was not only able to satisfy the requirements of our clients, but also received accolades from them for the fast delivery of improving their product standards. Do you want to know more about the secrets of this achievement and our journey of developing Data Science products in a time-constrained environment while meeting the requirements of the clients? Then, read the blog till the end.
2.
Differences between a Data Science Life Cycle and Software Development Life Cycle
The Conventional Software Development Life Cycle
An agreed upon convention for Software Development in companies is the Software Development Life Cycle (SDLC) to build software applications. It’s typically divided into six to eight steps: Planning, Requirements, Design, Build, Document, Test, Deploy, Maintain as explained in the blog article [1]. We do not need to discuss every step in detail, as the name describes the function as well. What we are particularly interested in is the culmination of both to build a product which internally performs Data-Science tasks and is built on Software technologies.

Figure 1 : Phases of Software Development Life Cycle (SDLC) [1]
Data Science Life Cycle
A general picture of the Data Science Life Cycle (DSLC) is described in the following figure [2].

Figure 2 : Phases of Data Science Life Cycle (DSLC) [2]
If we look at both of these cycles, we can see that the initial phase looks similar including planning, requirements and data investigation. In the SDLC, we have Design and in the DSLC we have Data Cleaning. In SDLC, we have the build phase, similarly in DSLC, we have the build or training of the model phase. Ultimately, we test the products; in SDLC we have the robust testing phase, whereas in DSLC, we also must enhance the model or improve the data quality.
In my experience, I found the data cleaning part the most time-consuming, as we need to gather data from different sources wrapped around in different formats. Furthermore, the quality of the data might not be appropriate. So, we might have to spend time looking through the data. Another important part is Annotation, which can also be time-consuming and boring sometimes. On the other hand, building a software product takes significant time as we may need to write algorithms and efficient code for both UI and the backend. In data science, the training of the model is the idlest time for programmers, during which we can sit back and relax. So, here, we would split up the work on corresponding Software Development tasks as the model is being trained. The allocation of the team is discussed in the following chapters.
3.
Our Project
We worked on projects which included designing a Data-Science Web App which our client’s employees would use to extract essential information with the help of Deep Learning models, store them in a database and retrieve them, when required, with the help of seamless UI experience. In the first stage, we had to work on identifying an initial workable piece of UI (User Interface) with a database. We used Java on the backend with db2 as the database as the customer had it on their part. We used Angular and Typescript to build the UI. Furthermore, we would always aim initially to create a Minimum-Viable-Product (MVP) without too much focus on UI/UX as our customer wanted to see the functionality. We started with building basic Add/Edit functionality so that the user can upload documents. After storing the information in the database, we could perform further functions.
In the second stage, we had to use the documents stored and perform Information-Extraction on them using DL models and Java libraries. This is the meat of the project. Around 80% percent of the time was spent on building the backend service which would perform the meaningful operations as intended by the customer. The complexity and the duration of the tasks would be varying as some tasks could involve building Deep Learning models for Information Extraction using NLP (Natural Language Processing) and Image Recognition and some others involving the use of libraries to calculate the similarity between texts.
4.
Tech Stack Prep of the Team
As a mountain trekker needs his proper gear for arduous tasks, a team requires proper understanding of the tech-stack involved during the entire life cycle of the project. In our case, our tech-lead and project manager had also motivated us to take on tough tasks, work on them and learn on the way.
- I know it sounds like motivational cheesy advice from a sage about life, but it works. -
In the beginning of the project, we were not acquainted with the industry relevant programming languages, such as Java and Typescript, for building backend and front-end parts respectively. However, after 9 months of working with them, the entire team can work easily and independently on the tasks assigned. All of these results from proper guidance from our tech-lead, but also the “can-do” attitude that we learned on our way.
5.
Problems
As we could observe from the differences of SDLC and DSLC, it could be difficult to estimate the time to build models for the software.
Annotations could take a lot of time
The whole team’s focus could go towards collecting, cleaning, and sorting the datasets for training. This is a halting period for the project as nothing tangible is happening, but it is also the most important part for building models. The quality of the data determines the quality of the model built. As we say in Data Science, “Garbage in, garbage out”.
Management of the team
As building the model became a priority, our team was divided 80 – 20; with 80 percent of the team working towards creating a reliable dataset for building Deep Learning Model and the 20 percent working on other tasks. Once the training data was at hand, the team was again split into 20 -80; 20 percent working on the Data Science task and 80 percent back to developing the product. Generally speaking, a single person can take care of the training of the models as it is time-consuming, and another person can monitor the progress and do the essentials.

Figure 3: Team separation
Iterations in Data Cleaning
Generally, while building the Deep Learning model, the most awaited phase is “testing” the model with real data to see its performance. All the efforts for so many days put together by all the team members lead up to this moment. The testing could lead to the expected output in the first attempt, but that’s hardly the case when training with real-life complex datasets. As the complexity of the dataset increases, the behaviour of the model changes as the model needs to learn the behaviour that is expected from the training data. To put it in a simple way, if we train a model to detect dogs and the model comes across new species looking like a pony or cat that was not present in training data, it will not classify them, as it didn’t learn to identify these species. In this case the expression “Garbage in, garbage out” applies here. To overcome unexpected problems while testing, the team would again think together about how it could improve the annotations and labelling so that the model gives the expected output.
Project Manager and the drastic pace of the Product
The project manager has the responsibility of planning, procurement, and execution of the project. As in a start-up, the role dividing boundaries are blurry, our Project Manager was loaded with tasks, and it would come on his shoulders to properly divide and explain them to the rest of the team. Sometimes, the developers would also get confused as the product would change so much over the course of time. The project manager would have to explain the new design or logic many times. This always happens with small teams. As our Project Manager was our CTO, there are numerous responsibilities on his shoulders. There would always be times, where a lot of dependency would fall on him, and he would be overloaded with meetings. If this could be mitigated, a lot of time could be saved. As the team grows over time, this problem could be solved by hiring a person only for this role. For that reason, our tech-exchange sessions were helping a lot. Here, we could describe our concerns and our strategies. We could also discuss the changes in the requirements of the client, future approaches, and we could have some personal discussions with the tech lead if he was available.
6.
The Sandwich Method
We followed the “Sandwich” method while designing and implementing our project for our client. The Sandwich method consists of layers of modules altering between Data Science Modules and Software Modules like the UI, database etc. The entire product was made with Typescript and Angular on the Frontend, and Java on the backend. The UI will help the user with typical functionalities, like adding a new document and changing information. The Data Science module is embedded in between, wherein the user can extract the information from the document. This option will shoot up the Deep Learning model and the model will give the results. The results are displayed to the user. Furthermore, the user can select to accept the result, if they find it useful or the user can also edit the result, if they think that it is not 100% perfect, but the inferences are still sufficient. This is the point where the human expertise meets with Deep Learning models. One can help the model perform better or could simply use the result provided. This is the point where you can see the Sandwich method, where the model is placed in the middle and users can help the model according to their requirements. This part helps prevent mistakes leading to bad results.
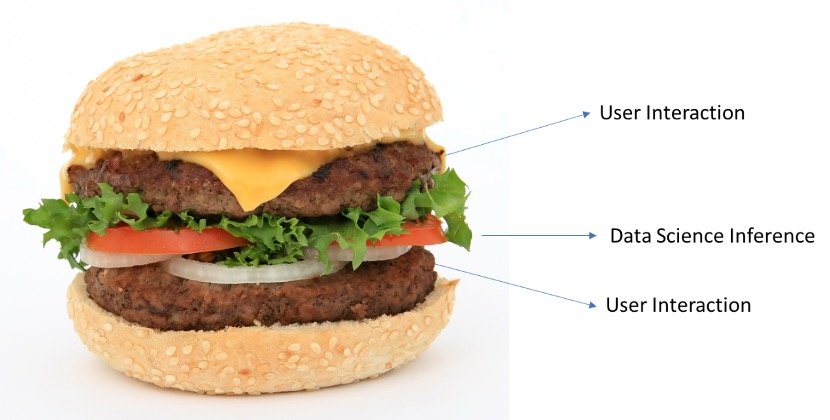
Figure 4: Sandwich Method
7.
Sprint and Weekly Reflections
We would carry out a 7-day sprint session with our every-day meeting at 8:30 am. It would be a 15-min meeting discussing what was accomplished the day before, what would be done today, any roadblocks faced etc. This is the staple routine followed in every agile company. We would also conduct tech-exchange sessions where we could discuss the major module added to the project and usage of some key tech-stacks, like Java Unit tests. These sessions would equip the team with better skills and would bring the team closer through discussion. The major beneficial factor, in my opinion, were the “Weekly Reflections”. Here, we would acknowledge the last week’s performance and results, and would plan the coming week’s goals accordingly. Afterwards, we would have our retrospective session where we would jot down the positives and negatives of the week. This has especially been helpful during the pandemic, as time flew like an arrow without us noticing it. There were times when I could not recollect what I did 3 days back, as I don’t journal daily. But this retro-session really offered me gratitude, filling me up with positive energy for the next week.
8.
Experience with the team
As our company is a start-up with a team of five data scientists, we can always connect with our team members in case of questions and doubts without much hesitation. The tech-stack always grows around us, and we need to accommodate it as fast as possible. As rightly put together by Napoleon Hill, “Struggle and Growth come only through continuous effort and struggle''. We have come a long way, and we will keep on growing. I would finally like to thank our CTO/ Project Manager, Thomas Keßler, for his patience and exceptional leadership skills. His positive criticism has motivated us constantly. Please keep in touch with our start-up and all its projects by hopping over to our website : https://www.genie-enterprise.com
References